

















What We Do
Psychometrics, Assessment, Leadership Potential,
Machine Learning & AI Bias Audits.

Psychometrics
High quality psychometrics available on our web based testing platform:
- Habitus – personality at work
- Foresight – business problem solving ability
- Signature – leadership potential
Our psychometric testing platform offers flexibility around assessment inputs and reporting outputs.

Assessment
Customised assessments for a range of sophisticated clients, including:
- Deep-dive interviews and work samples
- Full-day simulations
- Two-day assessment and development centres with all the trimmings
These assessments have supported decision making for graduates through to emerging, middle and senior leaders.

Leadership
Independent and objective measurement of a leader’s strengths and development needs through:
- 360 degree feedback surveys
- Exploratory psychological interviews
- Targeted simulations
Clients use these insights to support coaching, leadership / talent development activities or to inform final stage interviews.

Machine Learning
AI, machine learning, big data, fancy stats – whatever you like to call it, we have fun playing with numbers and ensuring our models link to real world outcomes. Some highlights include:
- Analysing 5M emails to create social networks that predict High Potential leaders.
- Matching tens of thousands of school kids to over 900 careers.
- Correctly picking the winner of the Melbourne Cup horse race two years in a row.
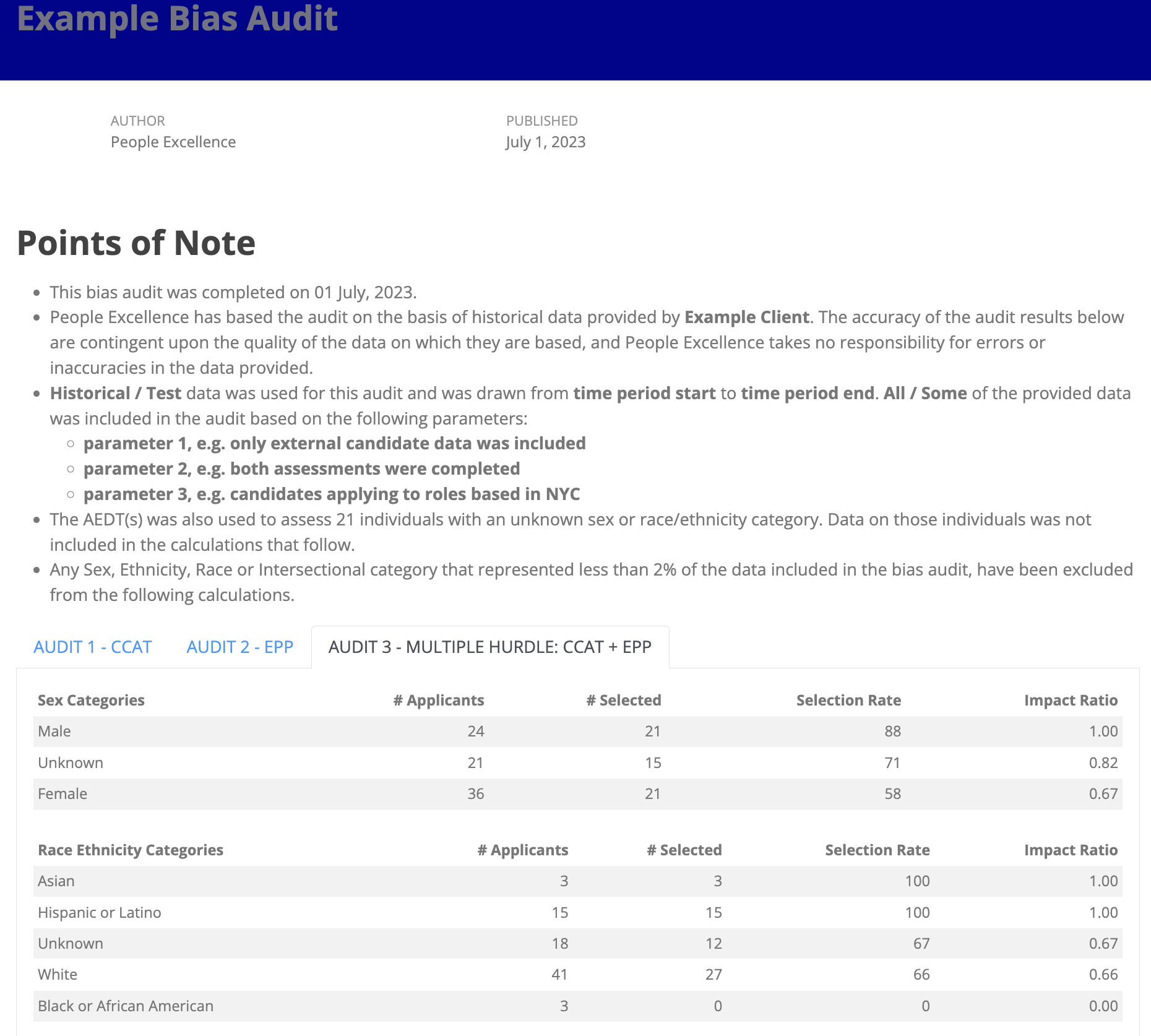
AI Bias Audits
In line with NYC Local Law 144, we deliver bias audits through an impartial & independent evaluation of automated employment decision tools (AEDT).
These bias audits analyse an AEDT for discrimination against the protected categories of sex, race/ethnicity, or intersections of these.
Book A Demo.
See how simple managing your own psychometric testing can be
See how simple managing your own psychometric testing can be